
Big Data et Santé :
les enjeux nationaux et illustrations empiriques à l’étranger
Par Matthias Fille, International Development - ICT
Advisor chez CCI Paris IdF
Il existe de
nombreuses perspectives de réutilisations innovantes des données publiques de
santé. L’analyse de ces Big Data santé
repose sur plusieurs bénéficies majeurs : une meilleure prise en charge du
patient (passer d’une logique curative à préventive), contenir drastiquement
les dépenses nationales (doublement de la population sénior d’ici 2030) et
offrir de nouveaux terrains d’analyses et expérimentations à la communauté de
recherche scientifique (épidémiologie, maladies chroniques, pharmacovigilance,
…)
La CNAM, un
vivier numérique inexploité
Notre modèle de santé se doit de faire mieux avec moins. Il doit être
vecteur d’amélioration du parcours de soins et doit replacer le citoyen au
centre du parcours de soins. Par extension, il doit être challengé de manière
vertueuse en s’appuyant à bon escient sur les outils de d’analyse prédictive et
de machine learning. En France, les données de santé sont consolidées par
la CNAM[1]. Ainsi, ce gisement de data n’est ni plus ni moins que la base de données
la plus étoffée au monde toutes catégories confondues. Ainsi, le SNIIRAM[2] retraite et
stocke 1,2 milliard de feuilles de soins chaque année (consommation et
prescription médicale, pathologie), 500 millions d’actes médicaux et 15
millions de séjours hospitaliers d’un peu plus de 65 millions d’individus. Soit
20 milliards
de lignes de prestations depuis 15 ans. Une véritable mine d’or inexploitée, un véritable
asset numérique dont dispose l’hexagone. Et ce depuis 15 ans. Soit 450
téraoctets de données.
La CNAM se refuse, à ce jour, de libérer ces informations. Or, elles pourraient
servir la recherche pour mieux appréhender les épidémies, qualifier les
prescriptions, jauger l’efficacité des médicaments, recouper des informations
pour prévenir de drames sanitaires ou comparer les frais médicaux. Tous les
analystes s’accordent sur le fait qu’une veille sanitaire calquée sur l’analyse
de ces données de la CNAM auraient endigué à coup sûr le mésusage inapproprié
d’un médicament comme le Mediator, via le recoupage et la mise en évidence de
facteurs de corrélation. On estime à environ
6000 par an le nombre de décès attribuables à des prescriptions injustifiées. Mais
l’accès à ces datas sont verrouillés. Ainsi l’efficience de notre système de
santé est sacrifiée sur l’autel de l’opacité. Non libérée, car cette
information représente le
principal levier de négociations avec les assureurs, les laboratoires, les
syndicats professionnels et les industriels. De plus lever le voile sur cette
opacité démontrerait au grand jour les insuffisances de la CNAM et l'inefficience à réguler et piloter les dépenses de santé et à optimiser le système de santé.
Pour l’ineptie, il faut savoir que jusqu’à peu, l'Institut de Veille Sanitaire n'avait pas accès au SNIIRAM. Or, l’accès à ces datasets permettrait de cerner tous nos excès et dérives : les prescriptions excessives de médicaments placebo[3] (sans aucun effet pharmacologique) et antibiotiques, les dépassements d’honoraires systématisés, la multiplication des arrêts de travail non justifiés, les fraudes à l’assurance maladie ou le recours trop systématique à la prescription « chimique ». Optimisée, elle permettrait de réaliser de fortes économies sans toucher à la qualité des soins. C’est d’ailleurs le combat entrepris par le collectif Initiative Transparence Santé[4]. Aujourd’hui, le médecin de ville est seul à décider de ses prescriptions. Dès lors que celles-ci sont susceptibles d’être analysées et comparées à la moyenne des prescriptions, le médecin et le système se retrouveraient « challengés » de manière vertueuse.
Pour l’ineptie, il faut savoir que jusqu’à peu, l'Institut de Veille Sanitaire n'avait pas accès au SNIIRAM. Or, l’accès à ces datasets permettrait de cerner tous nos excès et dérives : les prescriptions excessives de médicaments placebo[3] (sans aucun effet pharmacologique) et antibiotiques, les dépassements d’honoraires systématisés, la multiplication des arrêts de travail non justifiés, les fraudes à l’assurance maladie ou le recours trop systématique à la prescription « chimique ». Optimisée, elle permettrait de réaliser de fortes économies sans toucher à la qualité des soins. C’est d’ailleurs le combat entrepris par le collectif Initiative Transparence Santé[4]. Aujourd’hui, le médecin de ville est seul à décider de ses prescriptions. Dès lors que celles-ci sont susceptibles d’être analysées et comparées à la moyenne des prescriptions, le médecin et le système se retrouveraient « challengés » de manière vertueuse.
Vers une
médecine personnalisée et préventive
L’intégration du numérique
et l’exploitation de la data comme outil analytique permettrait de tendre vers
une médecine personnalisée, granulaire, préventive (donc plus efficace) et
moins coûteuse. En effet, notre médecine traditionnelle, obéit à des impératifs
qui ne prennent que trop peu en compte l’environnement multifactoriel dans
lequel évolue le patient au quotidien. Et dérive, de fait, vers des parcours de
soins « taylorisés », « protocolés ». Il est dénué de sens que deux personnes souffrant
d’une même pathologie reçoivent, selon un protocole de soin standard, un
traitement identique. Or la communauté médicale pourrait tirer profit de
l’analyse de ces datas. Il pourrait mieux appréhender notre
« rythmique de vie » et donc faire face aux risques potentiels via
cette nouvelle grille de lecture du parcours de vie. Car c’est en croisant ces
data que la posologie, les choix thérapeutiques la prédisposition ou les
indicateurs de récidive à certaines maladies chroniques pourraient être mieux
adaptés. En ayant à disposition de nouveaux outils d’aide à la décision basés
sur l’empirisme analytique de la data, le praticien pourra mieux arbitrer sur
les modalités d’intervention.
Car il lui manque aujourd’hui une transversalité collaborative et une
interdisciplinarité de l’analyse des données. Non pas in fine pour se limiter à
un meilleur traitement curatif et optimiser l’existant. Mais bien pour explorer
de nouveaux horizons préventifs : anticiper de manière prédictive de prochaines
pathologies pouvant subvenir. Par extension, le système de santé opérerait une
mue organisationnelle (processus et protocoles métier, optimisation des
allocations de ressources). Ces nouveaux horizons abaisseraient notre intensité
médicamenteuse (dimension chimique) et notre recours systématique aux services d’urgence. Notre
système se révèlerait plus efficient et à moindre coût pour la société. Cela
répondrait par ailleurs aux enjeux de de proximité, de personnalisation et de
prise en compte de ses spécificités individuelles voulues par le patient.

Le patient est
prêt
Désormais, le patient est engagé.
Il devient un générateur volontaire d’un corpus d’informations relatives au
domaine de la santé. En effet, l’information n’est plus en silos compartimentés.
Elle est devenue ubiquitaire. Le patient s’auto-responsabilise, il interagit. Il
veut prendre parti de l’actif informationnel qu’il génère. Avec cette vague du
Quantified Self, il se couvre de devices connectés (bracelets, balances
intelligentes, t-shirt enregistrant les battements de cœur, …) qui balayent ses
comportements alimentaires, comportements sportifs, humeurs, bien-être,
prédispositions, habitudes, indice de masse corporelle, performances
cognitives.
Il s’agit de véritables extensions du système nerveux
capables de détecter potentiellement en amont les premiers signes d’une maladie.
Ces devices interconnectés automatisent la collecte de données et en font
naître un usage. On parle ici des solutions combinant capteurs connectés et
applications sur smartphone (Fitbit, NikeFuelband, Jawbone, Withings, …) indiquant
vitesse, distance,
calories brulées, rythme cardiaque, pression artérielle, glycémie, hypertension,
cycles du sommeil. Ainsi, les flux d’informations de ces little data transmis en temps réel aux praticiens
pourraient modifier en profondeur la compréhension du mode de vie d’un patient
et des maladies chroniques. Sans nul doute, cela améliorait la réponse de la
santé publique. Il parait ubuesque d’être le pays champion
des objets connectés (Netatmo, Withings, Parrot, etc..) et ne pas être en
mesure de l’expérimenter à grande échelle sur la santé publique.
Par ailleurs, le patient exige de la transparence, par exemple sur les tarifs médicaux ou les dépassements d’honoraires. Il est demandeur et consommateur d’applications et de services de réutilisations innovants lui permettant de mieux arbitrer et appréhender son accès au parcours de soins. Il convient de recentrer le patient au cœur de la plate-forme de santé via la data. Il doit pouvoir accéder à ses données et en reprendre le contrôle aussi bien pour le droit à l’oubli que pour l’exploitation de celles-ci s’il veut en tirer en bénéfice. De surcroît, Pourquoi ne pas imaginer que le patient se réapproprie ses données ou qu’il lègue volontairement sa banque de données numériques à la recherche, plutôt que la CNAM en soit la gardienne. Mais, cela nécessite l’obtention de données objectives. Ainsi, il est grand temps pour le système de santé d’appréhender cette nouvelle rupture de paradigme où le patient n’est plus considéré comme un simple administré. Cette relation au patient passif est révolue.
L’open data pour la recherche
Les données de santé sont fondamentalement majeures pour produire de la connaissance scientifique et de la recherche avancée. La possibilité d’avoir accès à ces datasets permettrait des études cliniques à grande échelle sur l’épidémiologie, la pharmacovigilance ou l’efficacité et les effets secondaires d’un traitement. Car les travaux de la communauté scientifique requièrent une classe d’étude plus conséquente que celles d’essais cliniques classiques. C’est la dimension participative et contributive de la recherche de demain, où les données des patients s’enrichissent les unes des autres pour un bénéfice sociétal. Et le format de travail Open Data permet de connecter en réseau les communautés, fédère les expertises et courcicuite les rouages de fonctionnement cloisonnées et corporatistes. Ces données représentent un fabuleux terrain d’expérimentation pour la recherche approfondie. L’étude à l’échelle d’une population ou sur une couche de population précise permettrait de nouveaux angles d’approches sur les diagnostics et la connaissance maladie.
C’est notamment le cas pour croiser les corrélations entre le patrimoine génétique et certaines maladies comme le cancer (phénotype) à la recherche de signaux rares. L’étude de fonctionnement de la génomique et la protéomique, à l’heure de l’open data massif, permettrait de mieux anticiper les évolutions d’une maladie. Après l'effondrement du coût du séquençage ADN, l'enjeu majeur est désormais dans la capacité à exploiter les données génomiques. Ainsi, nous devons, en France changer le PH de l’aquarium pour créer un environnement adapté à ce type de recherches, et permettre d’oser, d’expérimenter sur ces sujets aussi critiques.
A l’étranger, de nombreuses initiatives de recherche et applications
Aussi, la réflexion nationale doit se nourrir des expérimentations et des illustrations empiriques à l’étranger. Par exemple en Italie, les autorités publiques s’attaquent à la fraude à l’assurance maladie. Le croisement automatique des données de l’assurance maladie avec celles disponibles en libre accès sur les réseaux sociaux permet d’identifier les arrêts maladie susceptibles d’être frauduleux par leur date ou leur récurrence.
En Australie, de très nombreuses informations relatives au système de santé sont mises en ligne, comme par exemple My Hospitals qui permet de comparer la performance des hôpitaux. D’une donnée libérée est né un usage.
Par ailleurs, le patient exige de la transparence, par exemple sur les tarifs médicaux ou les dépassements d’honoraires. Il est demandeur et consommateur d’applications et de services de réutilisations innovants lui permettant de mieux arbitrer et appréhender son accès au parcours de soins. Il convient de recentrer le patient au cœur de la plate-forme de santé via la data. Il doit pouvoir accéder à ses données et en reprendre le contrôle aussi bien pour le droit à l’oubli que pour l’exploitation de celles-ci s’il veut en tirer en bénéfice. De surcroît, Pourquoi ne pas imaginer que le patient se réapproprie ses données ou qu’il lègue volontairement sa banque de données numériques à la recherche, plutôt que la CNAM en soit la gardienne. Mais, cela nécessite l’obtention de données objectives. Ainsi, il est grand temps pour le système de santé d’appréhender cette nouvelle rupture de paradigme où le patient n’est plus considéré comme un simple administré. Cette relation au patient passif est révolue.
L’open data pour la recherche
Les données de santé sont fondamentalement majeures pour produire de la connaissance scientifique et de la recherche avancée. La possibilité d’avoir accès à ces datasets permettrait des études cliniques à grande échelle sur l’épidémiologie, la pharmacovigilance ou l’efficacité et les effets secondaires d’un traitement. Car les travaux de la communauté scientifique requièrent une classe d’étude plus conséquente que celles d’essais cliniques classiques. C’est la dimension participative et contributive de la recherche de demain, où les données des patients s’enrichissent les unes des autres pour un bénéfice sociétal. Et le format de travail Open Data permet de connecter en réseau les communautés, fédère les expertises et courcicuite les rouages de fonctionnement cloisonnées et corporatistes. Ces données représentent un fabuleux terrain d’expérimentation pour la recherche approfondie. L’étude à l’échelle d’une population ou sur une couche de population précise permettrait de nouveaux angles d’approches sur les diagnostics et la connaissance maladie.
C’est notamment le cas pour croiser les corrélations entre le patrimoine génétique et certaines maladies comme le cancer (phénotype) à la recherche de signaux rares. L’étude de fonctionnement de la génomique et la protéomique, à l’heure de l’open data massif, permettrait de mieux anticiper les évolutions d’une maladie. Après l'effondrement du coût du séquençage ADN, l'enjeu majeur est désormais dans la capacité à exploiter les données génomiques. Ainsi, nous devons, en France changer le PH de l’aquarium pour créer un environnement adapté à ce type de recherches, et permettre d’oser, d’expérimenter sur ces sujets aussi critiques.
A l’étranger, de nombreuses initiatives de recherche et applications
Aussi, la réflexion nationale doit se nourrir des expérimentations et des illustrations empiriques à l’étranger. Par exemple en Italie, les autorités publiques s’attaquent à la fraude à l’assurance maladie. Le croisement automatique des données de l’assurance maladie avec celles disponibles en libre accès sur les réseaux sociaux permet d’identifier les arrêts maladie susceptibles d’être frauduleux par leur date ou leur récurrence.
En Australie, de très nombreuses informations relatives au système de santé sont mises en ligne, comme par exemple My Hospitals qui permet de comparer la performance des hôpitaux. D’une donnée libérée est né un usage.
 Au Royaume-Uni, dès Décembre 2012, l’institut pour les Données Ouvertes[5] a
mis à disposition les Open Data de santé. L’ODI a été lancé par Sir Tim Berners-Lee,
inventeur du World Wide Web et Dr. Nigel Shadbolt, spécialiste du Web
Sémantique et membre du Government Transparency Board, et du gouvernement de
David Cameron. Il vise « la collaboration entre les entreprises, les
entrepreneurs, les chercheurs, l’Etat et la société civile, pour concrétiser la
promesse de valeur économique et sociale liée aux grandes quantités de données
publiques désormais accessibles à tous et réutilisables par chacun ». Aux
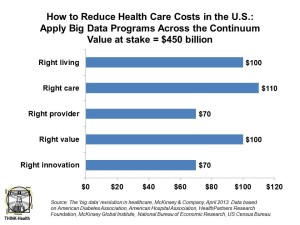
Etats-Unis, McKinsey estime que l’Open Data pourrait
faire économiser entre 300 et 450 milliards de dollars au système de santé
américain[6].
Au Royaume-Uni, dès Décembre 2012, l’institut pour les Données Ouvertes[5] a
mis à disposition les Open Data de santé. L’ODI a été lancé par Sir Tim Berners-Lee,
inventeur du World Wide Web et Dr. Nigel Shadbolt, spécialiste du Web
Sémantique et membre du Government Transparency Board, et du gouvernement de
David Cameron. Il vise « la collaboration entre les entreprises, les
entrepreneurs, les chercheurs, l’Etat et la société civile, pour concrétiser la
promesse de valeur économique et sociale liée aux grandes quantités de données
publiques désormais accessibles à tous et réutilisables par chacun ». Aux
Etats-Unis, McKinsey estime que l’Open Data pourrait
faire économiser entre 300 et 450 milliards de dollars au système de santé
américain[6].
Outre-manche,
existe le National Cancer
Registration Service qui a mis au point une giga base de données,
unique, extrêmement fournie sur les diagnostics et traitements du cancer. Il
consolide les données de l’alpha à l’oméga : diagnostics, réactions au
traitement, 1ers soins, traitements, suivi quotidien, résultats, soins
palliatifs jusqu’au décès. Cette
base de données est enrichie de 11 millions d'enregistrements sur le cancer et
s'agrandit tous les ans avec 350 000 nouveaux cas de tumeurs. Ses algorithmes produisent des
analyses prédictives sur la manière dont les patients réagissent le mieux aux
traitements. Les informations relatives à la progression du diagnostic et de la maladie sont
reliées aux analyses moléculaires et génomiques du patient. Et sur la « noblesse » du projet, autant être exemplaire jusqu’aux
choix technologiques et au degré d’ouverture : choix logiciels open source
et plate-forme de gestion projet agile, ouverture de l’accès au système et
renseignement des données par patients, création de passerelles scientifiques
avec la génomique.
Toujours au
Royaume-Uni, le Département de la Santé demande aux médecins d’encourager leurs
patients à avoir recours à des applications mobiles pour suivre leurs signes
vitaux et leurs symptômes dans toutes sortes de situations afin de réduire les
consultations inutiles. De plus, l’intensification de transmission de ces
données améliore les prises en charge ultérieures. Les applications
recommandées sont homologuées et gratuites.
Au Canada, a été lancé dès
2000, Génome Canada[7], qui a permis le
financement de projets innovants de big data génomique. Citons pêle-mêle, le
cas de l’entreprise GenePOC qui a mis au point un disque compact de diagnostic
utilisant des tests à base d’ADN ou celui de BD Diagnostic GeneOhm, une société de diagnostic moléculaire qui se classe au
premier rang parmi les développeurs de tests rapides visant à détecter et à
identifier une variété d’agents infectieux et de variations génétiques. Elle
aujourd’hui leader mondial de son domaine. Cet enjeu est générateur d’emploi,
de revenus et de solutions de santé.
Aux États-Unis, des projets de recherche
connexe ont généré 67 milliards de dollars pour l’économie américaine; 20
milliards de dollars en revenus et 310 000 emplois. Le
projet CATCH du MIT croise génétique et analyse passive des comportements des
patients atteints de diabète. En plus des informations médicales classiques sur
les patients, une équipe recueille et analyse les infos comportementales, la
géolocalisation les habitudes de vie transmises par leurs téléphones.
A
Singapour, les apports de l’analyse prédictive s’appliquent à la politique
organisationnelle de soins afin de mieux industrialiser ces processus
métiers : les données relatives aux patients réadmis dans
l’hôpital à plus de deux reprises dans un intervalle de six mois sont analysées
et servent à l’élaboration d’un modèle prédictif. Celui-ci permet d’anticiper
la demande de soins un mois à l’avance, notamment celle des patients qui
souffrent de maladies chroniques. L’hôpital affecte ainsi mieux ses ressources
et améliore la « user expérience » du patient au cours de son
parcours de soins. L’accès à l’information permet aussi une meilleure
coordination des services de santé et in fine de la pris en charge du patient.
En Norvège, les municipalités fluidifient l’accès à l’information via les
écrans tactiles de services et l’accès aux informations de services de santé. Pour
améliorer l’efficacité de services devant faire face à un flux d’information
important et continu, des écrans équipent les salles d’infirmières dans la
ville norvégienne et affichent l’état des chambres ou les patients en attente
pour obtenir d’un coup d’œil une meilleure vue d’ensemble.
Soulignons le projet européen Sim-e-Child appliqué à la cardiologie
pédiatrique. Cette plate-forme cloud permet aux praticiens de valider de nouveaux modèles de simulation concernant les pathologies
cardiaques complexes. La plateforme permet de s'affranchir des infrastructures
lourdes et des contraintes propriétaires des systèmes d'information. Les
cardiologues peuvent ainsi requêter une énorme base de données, les croiser et
obtenir des rendus statistiques. Il pourrait se convertir en outil d’aide à la
décision médicale : qualifier plus facilement le diagnostic des patients
et consulter des cas de référence. Ce modèle pourrait être décliné pour toutes
sortes de pathologies.
Les
Etats-Unis ont usé de procédés algorithmiques afin de procéder à des essais sur des échantillons cliniques plus grands, et ont
fait émerger des tendances que l’on n’aurait pas imaginées à l’avance. Par
exemple, en 2009, en pleine pandémie de grippe H1N1, le ministère américain a
eu recours aux services de Google. Via la collecte et la localisation des
recherches mots clés et données relatives, Google a pu anticiper l’évolution de
l’épidémie. Il a décliné cela Google Flu Trends, qui fournit en prédictif des
indicateurs de propagation de la grippe. En outre, les données recueillies sont
temps réel, très nombreuses, conditions sine qua non à l’étude de
l’épidémiologie.
Twitter s’intéresserait désormais à la dépression, fléau
sanitaire du 21ème siècle, après avoir étudié la progression
de la gastro-entérite. Une véritable création de valeur quand on sait que la
France détient le triste record de consommation de médicaments psychotropes… Le croissement de données permet d’appréhender des
phénomènes imperceptibles et d’améliorer la pharmacovigilance : le requêtage
sur Google de patients consommant du paroxetine et pravastin a permis de
comprendre que cela augmentait les risques en effet secondaire
d’hyperglycémie. Faute d’une position
volontariste de la CNAM, ce sont aujourd’hui les pure-players de la data (Google,
Twitter, …) qui participent à la veille épidémiologique via les analyses de
signaux. Ils pourraient aussi à terme s’intermédier entre le citoyen et les
praticiens et monétiser cette connaissance patients.
L’ONU quant à elle, via le projet Global Pulse analyse à un
niveau micro, les flux migratoires, la nature des intégrations sur les réseaux
sociaux, les pics soudains d’chats de denrée alimentaire / médicamenteuse. Ce
projet a pour ambition d’analyse cela en temps réel dans une logique prédictive
pour mieux appréhender les drames humanitaires, crises alimentaires ou
épidémies. Comme le souligne Henri verdier d’Etalab, la plupart des actions de
l'ONU ont besoin de données fiables, actionnables, et obtenues dans un délai
très court. Puisque désormais l'empreinte de presque toutes les activités
humaines et l’implication sociétale sont imprimées et géo-localisables dans les
réseaux numériques, il devient donc très tentant d'aller chercher, dans ces
données ouvertes et anonymisées, les éléments de décision dont l'organisation a
besoin.
Au Rwanda, les solutions de la start up Foyo[8],
s’appuie sur le vaste parc mobile[9] pour
toucher le plus grand nombre de patients. Leur application propose
aux patients de s'abonner afin de recevoir tous les jours un SMS leur
préconisant un régime équilibré et adapté à leur maladie (cancer, problèmes
cardiaques, diabète, obésité, sida et hépatites). Le volet participatif
s’enrichit par leur plate-forme m-Health d’échanges entre patients et
praticiens.
Saluons le prototype de canne intelligente connectée de
Fujistu. Une personne peut ainsi télécharger son itinéraire. La
personne est géo-localisée en permanence. Des capteurs de température et
d’humidité permettent d’évaluer un changement météo et de modifier l’itinéraire
pour mettre la personne à l’abri si nécessaire. La canne intègre également un
capteur de fréquence cardiaque.
Quant à elle, la
société Qualcomm, (historiquement spécialisée dans la conception processeurs
pour téléphones portables) vient de lancer 2net Mobile, application grand
public sous Android, qui permet d’agréger sur smartphones et tablettes des données cliniques (médicales et
biométriques) transmises par les capteurs de multiples dispositifs médicaux.
Cela fait écho à son produit d’infrastructure hub2net, qui lui répond au suivi
à domicile des patients atteints de maladies chroniques
Ainsi, on constate que les pouvoirs publics de la santé n’ont
pas suffisamment accéléré leur transition vers le numérique et la data. Aussi
bien sur les nouveaux usages, les compétences métiers que les infrastructures. Pour
les pays les plus précurseurs, le ratio de personnel
informatique est de 2 %, soit un spécialiste de l'IT pour 50 hospitaliers. En
France, il se situe péniblement à 0,4%. Exprimé en chiffre brut, ces écarts se
traduisent en dizaines de milliers d'emploi, par exemple 25000
en Angleterre contre 5000 en France. Quant aux infrastructures, le taux des
hôpitaux raccordés aux réseaux haut débit (>100Mbps) est
catastrophique : 25e place du classement continent européen. La France se
classe avant dernière en Europe en termes de disponibilité de système
d’archivage numérique d’images médicales. 16ème pour le déploiement
de la télémédecine. C’est ce genre de hiatus qui empêche une meilleure fluidification
des informations entre tous les acteurs traditionnels de santé.
Conclusion
Le bénéfice d’ouverture des données de santé est indéniable. L’éviter
relèverait d’un certain déni de réalité ou d’un obscurantisme à l’innovation et
au progrès scientifique. Il est regrettable de constater que de plus en plus
d’acteurs publics et collectivités libèrent leurs données, quand dans le même
temps, la CNAM campe sur une position cléricaliste et sclérosante. Certes, la crispation est légitime sur la menace de
l’utilisation frauduleuse de ces données.
Il revient ainsi aux pouvoirs publics
de mettre en place un cadre de confiance et d’éthique qui jugulerait les
dérives, garantisserait l’anonymisation des données et libérerait l’innovation
et la création de valeur. Tous les voyants sont convergents : les
technologies d’exploitation de Big Data sont matures, le patient interconnecté
est générateur de corpus d’information, il exige de la transparence et de la
personnalisation, les nouveaux usages ne demandent qu’à émerger. Il est ainsi
grand temps de libérer ces big data. A l’heure où notre système d’accès aux
soins se dégrade, où la santé à deux vitesses se confirme, où le financement
dérape, l’intégration des technologies d’exploitation de la data représente un
formidable levier de modernisation structurelle qui ne se discute plus. Ainsi,
de nouveaux champs disciplinaires verront le jour, mais tout cela est
conditionné au principe du droit à l’expérimentation.
Twitter @matt_fill
Twitter @matt_fill
[2] Système national
d’informations inter-régimes de l’Assurance maladie
[4] Initiative
Transparence Santé est un collectif d'acteurs œuvrant dans le domaine de la
santé qui réclame l'accès aux données publiques relatives à notre système de
soins (http://www.opendatasante.com/)
[8] lauréate du concours
SSW de Kigali
[9] 62,8% de la
population rwandaise utilise le mobile
Aucun commentaire:
Enregistrer un commentaire